预计阅读时间:3 分钟
这个功能主要是使用python的jieba分词模块来分词,然后使用mapreduce来统计,其实功能很简单,但是由于刚开始接触使用hadoop,出现了各种问题,这里记录下。
在hadoop执行的mapreduce程序时,使用python非系统模块的话会出现找不到包的错误,网上找到了一种解决方案,使用系统内置的zipimport模块,使用方法:
首先将该模块的所有文件复制到当前目录,然后执行:
zip -r jieba.zip jieba
mv jieba.zip jieba.mod
然后代码中就可以这样引入:
import sys
sys.path.append('./')
import zipimport
importer = zipimport.zipimporter('jieba.mod')
jieba = importer.load_module('jieba')
import jieba.analyse
执行的时候又提示错误.在import jieba.analyse时候报错找不到idf.txt这个文件,看了下jieba的源码才发现,在tfidf.py文件如下代码块:
_get_module_path = lambda path: os.path.normpath(os.path.join(os.getcwd(),
os.path.dirname(__file__), path))
_get_abs_path = jieba._get_abs_path
DEFAULT_IDF = _get_module_path("idf.txt")
需要读取idf.txt,因为我是使用压缩包导入的模块,而这样读取的话肯定是读取不到的,之后修改了源码,将上面代码块的最后一行修改为DEFAULT_IDF='idf.txt'
然后将执行MapReduce的命令中加上该文件:
hadoop jar /usr/local/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.8.2.jar \
-files ./mapper.py,./reducer.py,./jieba.mod,./idf.txt \
-mapper "python3 ./mapper.py" \
-reducer "python3 ./reducer.py" \
-input xiyouji/* -output xiyouji-output
终于可以成功执行了。 下面贴出源码 mapper.py:
#!/usr/bin/env python
import sys
sys.path.append('./')
import zipimport
importer = zipimport.zipimporter('jieba.mod')
jieba = importer.load_module('jieba')
import jieba.analyse
for line in sys.stdin:
line = line.strip()
results = jieba.analyse.extract_tags(line, topK=100)
resultdict = dict()
for s in results:
if s and s.strip():
if s in resultdict:
resultdict[s] += 1
else:
resultdict[s] = 1
if resultdict and len(resultdict):
for s in resultdict:
if s:
print('%s\t%s' % (s, resultdict[s]))
reducer.py:
#!/usr/bin/env python
from operator import itemgetter
import sys
import sys
sys.path.append('./')
current_word = None
current_count = 0
word = None # input comes from STDIN
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# print(line)
# parse the input we got from mapper.py
word, count = line.split('\t', 1)
# convert count (currently a string) to int
try:
count = int(count)
except ValueError:
# count was not a number, so silently
# ignore/discard this line
continue
# this IF-switch only works because Hadoop sorts map output
# by key (here: word) before it is passed to the reducer
if current_word == word:
current_count += count
else:
if current_word:
# write result to STDOUT
print('%s\t%s' % (current_word, current_count))
current_count = count
current_word = word
# do not forget to output the last word if needed!
if current_word == word:
print('%s\t%s' % (current_word, current_count))
使用
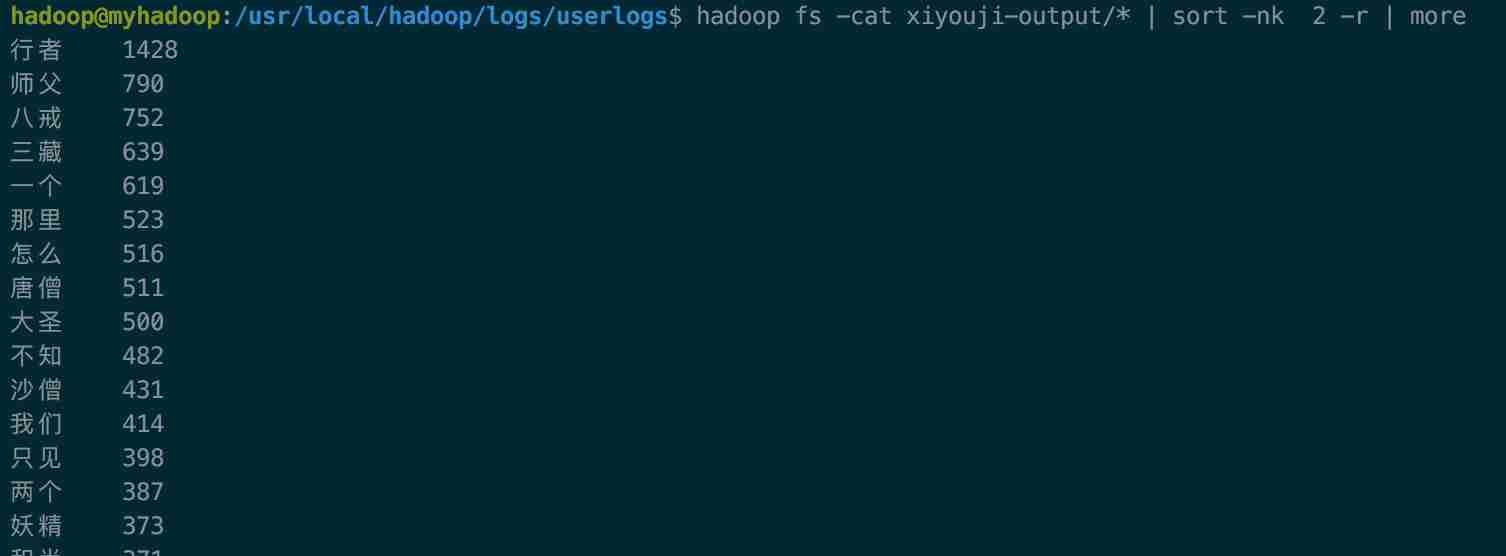
hadoop fs -cat xiyouji-output/* | sort -nk 2 -r | more
来查看结果.如下图。
本文由 liangliangyy 原创,转载请注明出处。